在昨天我們討論了 Overfitting 可能出現的幾種原因,以及要怎麼判斷 Overfitting。實際上在機器學習的模型結果會出現的問題大致上不是 Overfitting 就是 Underfitting。也就是說過分的貼合 Training Data,或是根本沒有貼合 Training Data。
今天我們來談談如果我們發現到模型結果並不理想,除了各種隨意調整參數以外,有沒有比較實際可以依循的步驟。
在昨天我們有稍微提過幾個比較常見造成 Overfitting 的原因,包含了底下四種。
並且在訓練模型的過程當中會經歷底下這些步驟。
我們也提及,如果把訓練資料切割成 Train、Test、Validation,並且把 Train Loss 以及 Test Loss 拿來繪製成圖,Validation 用於客觀評價一個模型最終結果,根據這個圖形你可以去評估現在模型的狀況。
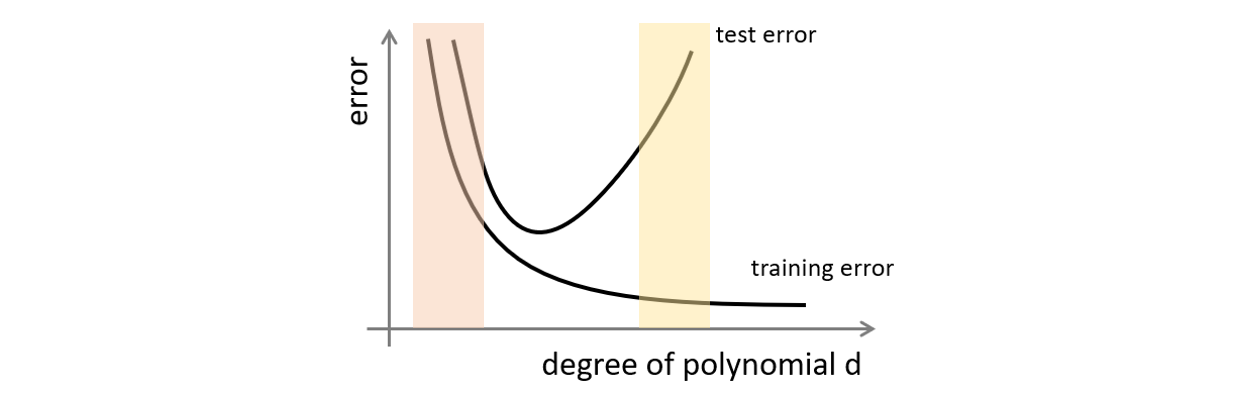
圖片修改自 2014 年 Andrew Ng Machine Learning 課程簡報
接下來來看看該如何解決模型出現的問題。
聽說當模型不夠好的時候,取得更多的資料一定會有好的幫助,不過這並不盡然。取得更多的訓練資料,更多時候我們講的是希望獲得 更貼近現實的普遍資料 。
所以採取 取得更多訓練資料 這個手段會在 Overfitting 的時候有幫助,它可以讓你的模型學習到更多廣泛的資訊。
反之,如果你打算在 Underfitting 的情況下使用這個方法很可能是沒幫助的。下圖是一個視覺化的例子,可以看到原本模型其實就沒有很好的 fit 在資料上,但是資料本身的廣泛度已經足夠了。現在如果再新增更多的資料進來,對於模型的訓練會沒什麼幫助。
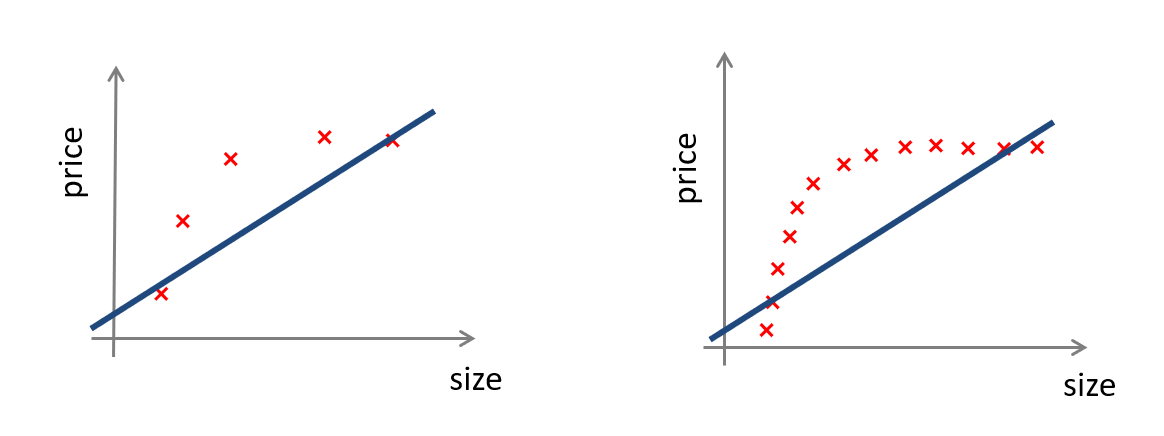
圖片修改自 Andrew Ng 2014 Machine Learning 課程簡報
前面提及模型訓練 Overfitting 的原因之一是因為 模型複雜度過高 ,也如同昨天舉的例子,因此解決的方法也就正好相反,試著把複雜度降低。
通常會以相同的手法,但不同的模型複雜度下去訓練,接下來去比較哪一個比較好,就選擇這樣的模型複雜度。
所以像是昨天的例子當中,如果一開始選擇了 degree 為 30 的模型發現會 Overfitting,那也許你可以試著將 degree 調小,讓模型出現奇怪形狀、複雜度增加的機會降低。
反之,如果在 Underfitting 的狀況下降第模型複雜度,那只會讓你的模型表現能力更加差勁,造成更壞的影響。
有降低複雜度,自然就會有增加複雜度。如果你的模型本來就不夠具備廣泛性,那應該要試著增加模型的複雜度。
模型複雜並不表示這是壞的模型,想想那些現在在市面上看得到的模型哪個不是相當複雜的模型。所以並不是每次我們都會去把模型複雜度調小來解決 Overfitting,有時候我們會在 Loss Function 上加上 Regularzation Term。
Regularization 的想法是,也許模型可以更新到一個 Loss 最小的點,但是缺乏了泛化能力。那我願意犧牲一在 Training 上的精確度,但讓模型有更好的表現性。
透過限制模型能夠更新的範圍來侷限住模型發展,不讓它跑到原先的最小值上。
這一篇由 Allen Tzeng 撰寫的文章 以數學的角度出發說明 Regularization 做了什麼,我覺得寫得很好,很值得參考。
實作面上我們是小小修改了 Loss Function,在後面加上了 Regularization。而實際上 Regularization 也有許多種類,底下是 L2 Norm 的例子。
其中, 可以控制 Regularization 的大小,也是一個 Hyperparameter 。
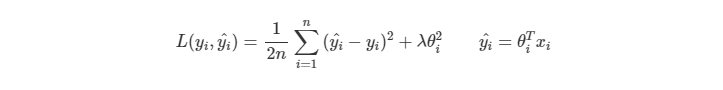
在 Gradient Descent 的步驟上變成需要多考慮到後面的 Term,底下是原先的 Gradient Descent。
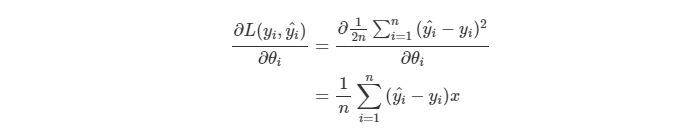
會變成
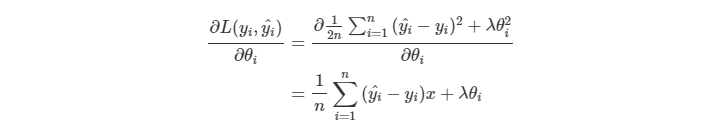
透過調整 的大小會造成不同的效果。
因此,在不同情況下會選擇不同調整方向
有時候原本的資料廣泛度雖然足夠,但就敗在整體的 Feature 不足以看穿整個問題本質。就像是要你單純從身高體重去預測一個人的數學成績,你可能蒐集足夠多的學生資料,並且高矮胖瘦都有,但是這些資料再齊全,你也無法從中推測結論,這時候就需要擴充更多 Feature 了。
換言之,這通常會是在模型 Underfitting 的狀況下決定要新增更多的 Feature。
有擴充就自然會有減少。如同我們在實作 Classification 的時候我們會直接把看起來不相關的流水號直接移除,避免模型為了要 fit 這個不相干的數據而有不好的結果產生。
有時候你可以做一些實驗,用不同的 Feature 訓練許多模型去驗證某些 Feature 存在會使得模型訓練效果差。有時候則是會先觀察一下 Feature 與輸出的相關性。
在 Learning Rate 的設定上我們會習慣從比較小的 Learning Rate 開始嘗試,不過如果你發現到模型的 Train Loss 和 Test Loss 都有順利下降,不過還沒有開始收斂,那也許是因為 Learning Rate 過小,導致模型更新速度太慢。
有時候則是 Learning Rate 是可以的,但需要多訓練幾個 epochs。
建議可以設定比較高的 epoch,把每數個 epoch 後的訓練結果儲存起來,如果你發現模型已經開始收斂,那就把訓練中止即可。
後續也會提到其他調整 Learning Rate 的方法,不過現階段先認知到 Learning Rate 大小會影響到收斂的速度即可。
有時候你的 Learning Rate 設定太高,會導致你的模型沒辦法滾到 Loss 的最低點,而是在來回震盪。

圖片取自 JEREMY JORDAN 部落格文章 Setting the learning rate of your neural network.
如果你發現到 Train Loss 有來回震盪的狀況,很可能是因為 Learning Rate 太高了,此時應該要降低 Learning Rate。
今天我們講述了當遇到 Overfitting 或 Underfitting 時我們應該有哪些手段可以採用,比較簡單的整理如下表。不過實際上遇到這些狀況的時候,還是到上面詳細看一下造成的原因以及解決手段。
| 方法 | 解決目標 |
|---|---|
| 取得更多訓練資料 | Overfitting |
| 降低模型複雜度 | Overfitting |
| 增加模型複雜度 | Underfitting |
| 提高 Regularization 係數 | Overfitting |
| 降低 Regularization 係數 | Underfitting |
| 擴充資料 Feature | Underfitting |
| 減少資料 Feature | Overfitting |
| 提高 Learning Rate、增加 epochs | Underfitting |
| 降低 Learning Rate | Underfitting |
每次當遇到模型訓練出問題時,先確定現在遇到的問題是 Underfitting 還是 Overfitting,接下來思考在這些可能的解決方案當中,何者造成的可能性最高,需要花費的成本最低,就先試著往這個方向做做看。

